系统学习 redis 相关的知识,从数据结构开始~
String 字符串
Redis 的字符串是 动态字符串, 长度可变,自动扩容。利用预分配空间方式减少内存的分配。默认分配 1M 大小的内存。扩容时加倍现有空间,最大占用为 512M.
常用命令
结构
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位,不理睬它
byte [] content; // 数组内容
}
Redis 中的字符串叫做 Simple Dynamic String, 上述 struct 是一个简化版,实际的代码中,redis 会根据 str 的不同长度,使用不同的 SDS, 有 sdshdr8, sdshdr16, sdshdr32 等等… 但结构体都是如上的类型.
capacity 存储数组的长度,len 表示数组的实际长度。需要注意的是: string 的字符串是以 \0 结尾的,这样可以便于调试打印,还可以直接使用 glibc 的字符串函数进行操作.
字符串存储
字符串有两种存储方式,长度很短时,使用 emb 形式存储,长度超过 44 时,使用 raw 形式存储.
可以使用 debug object {your_string} 来查看存储形式
> set codehole abcdefghijklmnopqrstuvwxyz012345678912345678
OK
> debug object codehole
Value at:0x7fec2de00370 refcount:1 encoding:embstr serializedlength:45 lru:5958906 lru_seconds_idle:1
> set codehole abcdefghijklmnopqrstuvwxyz0123456789123456789
OK
> debug object codehole
Value at:0x7fec2dd0b750 refcount:1 encoding:raw serializedlength:46 lru:5958911 lru_seconds_idle:1
WHY?
首先需要解释 RedisObject, 所有 Redis 对象都有的结构体
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes
void *ptr; // 8bytes,64-bit system
} robj;
不同的对象具有不同的类型 type (4bit),同一个类型的 type 会有不同的存储形式 encoding (4bit),为了记录对象的 LRU 信息,使用了 24 个 bit 来记录 LRU 信息。每个对象都有个引用计数,当引用计数为零时,对象就会被销毁,内存被回收。ptr 指针将指向对象内容 (body) 的具体存储位置。这样一个 RedisObject 对象头需要占据 16 字节的存储空间。
接着我们再看 SDS 结构体的大小,在字符串比较小时,SDS 对象头的大小是 capacity+3,至少是 3。意味着分配一个字符串的最小空间占用为 19 字节 (16+3)。
一张图解释:

List 列表
Redis 的列表是用链表来实现的,插入删除 O (1), 查找 O (n), 列表弹出最后一个元素时,数据结构删除,内存回收.
常用命令
列表的数据结构
列表底层的存储结构并不是简简单单的一个链表~通过 ziplist 连接起来组成 quicklist.
ziplist 压缩列表
在列表元素较少时,redis 会使用一块连续内存来进行存储,这个结构就是 ziplist. 所有的元素紧挨着存储.
> zadd z_lang 1 java 2 rust 3 go
(integer) 3
> debug object z_lang
Value at:0x7fde1c466660 refcount:1 encoding:ziplist serializedlength:34 lru:11974320 lru_seconds_idle:11
可以看到上述输出 encoding 为 ziplist.
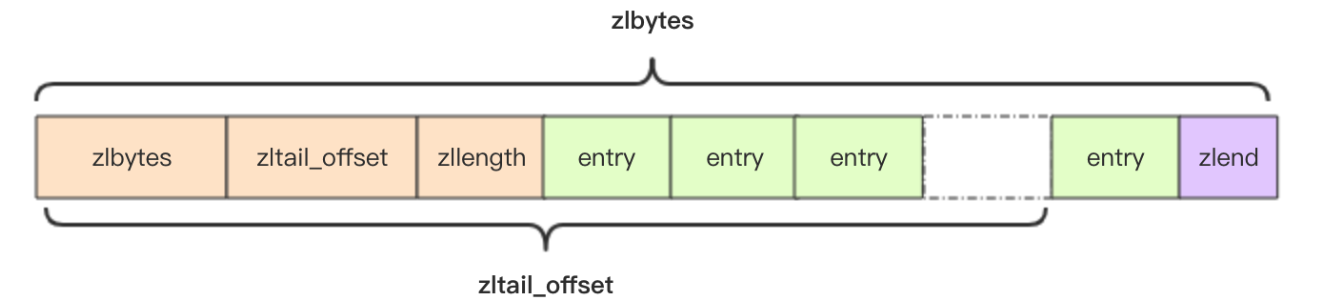
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T [] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
zltail_offset 是为了支持双向遍历才设计的,可以快速定位到最后一个元素,然后倒着遍历.
entry 会随着容纳的元素不同而结构不同.
struct entry {
int<var> prevlen; // 前一个 entry 的字节长度
int<var> encoding; // 元素类型编码
optional byte [] content; // 元素内容
}
prevlen 表示前一个 entry 的字节长度,倒序遍历时,可以根据这个字段来推算前一个 entry 的位置。它是变长的整数,字符串长度小于 254 ( 0XFE ) 时,使用一个字节表示,大于等于 254, 使用 5 个字节来表示。第一个字节是 254, 剩余四个字节表示字符串长度.

encoding 编码类型
encoding 存储编码类型信息,ziplist 通过其来决定 content 内容的形式。所以其设计是很复杂的.
00xxxxxx最大长度位 63 的短字符串,后面的 6 个位存储字符串的位数,剩余的字节就是字符串的内容。01xxxxxx xxxxxxxx中等长度的字符串,后面 14 个位来表示字符串的长度,剩余的字节就是字符串的内容。10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd特大字符串,需要使用额外 4 个字节来表示长度。第一个字节前缀是10,剩余 6 位没有使用,统一置为零。后面跟着字符串内容。不过这样的大字符串是没有机会使用的,压缩列表通常只是用来存储小数据的。11000000表示 int16,后跟两个字节表示整数。11010000表示 int32,后跟四个字节表示整数。11100000表示 int64,后跟八个字节表示整数。11110000表示 int24,后跟三个字节表示整数。11111110表示 int8,后跟一个字节表示整数。11111111表示 ziplist 的结束,也就是 zlend 的值 0xFF。1111xxxx表示极小整数,xxxx 的范围只能是 (0001~1101), 也就是1~13,因为0000、1110、1111都被占用了。读取到的 value 需要将 xxxx 减 1,也就是整数0~12就是最终的 value。
增加元素
ziplist 是连续存储的,没有多余空间,这意味着每次插入一个元素,就需要扩展内存。如果占用内存过大,重新分配内存和拷贝内存就会有很大的消耗。所以其缺点是不适合存储 大型字符串, 存储元素不宜 过多.
级联更新
每一个 entry 都是有 prevlen, 而且时而为 1 字节存储,时而为 5 字节存储,取决于字符串的字节长度是否大于 254, 如果某次操作导致字节长度从 254 变为 256, 那么其下一个节点所存储的 prevlen 就要从 1 个字节变为 5 个字节来存储,如果下一个节点刚好因此超过了 254 的长度,那么下下个节点也要更新… 这就是级联更新了~
quicklist
Redis 中 list 的存储结构就是 quicklist. 下面的 language 是一个记录编程语言的集合。可以看到 encoding 即为 quicklist.
> debug object language
Value at:0x7fde1c4665f0 refcount:1 encoding:quicklist serializedlength:29 lru:11974264 lru_seconds_idle:62740 ql_nodes:1 ql_avg_node:3.00 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:27
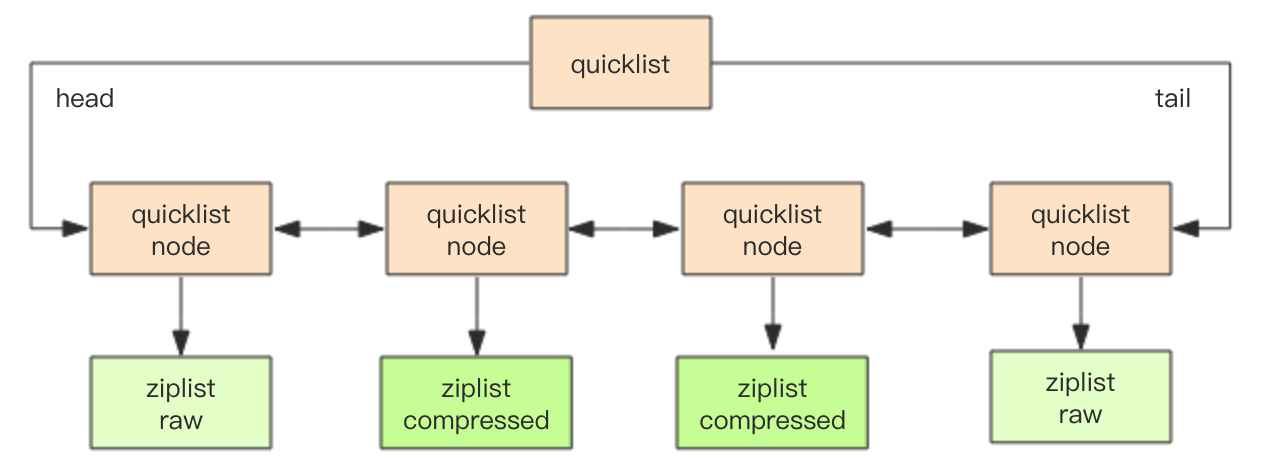
Redis 的 quicklist 是一种基于 ziplist 实现的可压缩(quicklistLZF)的双向链表,结合了链表和 ziplist 的 优点 组成的。下面可以看下他的结构体.
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
/**
* quicklist 是一个 40byte (64 位系统) 的结构
*/
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* 元素总数 */
unsigned long len; /* quicklistNode 的长度 */
int fill : 16; /* ziplist 的最大长度 */
unsigned int compress : 16; /* 节点压缩深度 */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; /* 没有压缩,指向 ziplist, 否则指向 quicklistLZF
unsigned int sz; /* ziplist 字节总数 */
unsigned int count : 16; /* ziplist 元素数量 */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
...
} quicklistNode;
//LZF 无损压缩算法,压缩过的 ziplist
typedef struct quicklistLZF {
// 未压缩之前的大小
unsigned int sz; /* LZF size in bytes*/
// 存放压缩过的 ziplist 数组
char compressed [];
} quicklistLZF;
一张图展示结构
压缩深度
quicklist 默认的压缩深度是 0,也就是不压缩。压缩的实际深度由配置参数 list-compress-depth 决定。为了支持快速的 push/pop 操作,quicklist 的首尾两个 ziplist 不压缩,此时深度就是 1。如果深度为 2,就表示 quicklist 的首尾第一个 ziplist 以及首尾第二个 ziplist 都不压缩。
Set 集合
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
常用命令
SADD,SMEMBERS,SPOP,SISMEMBER,SCARD…
Hash 哈希
Redis 的 Hash相当于Java 中的 HashMap, 数组 + 链表的二维结构.与 HashMap 不同的地方在于 rehash 方式不同, HashMap 中的 rehash 是阻塞式的, 需要一次性全部 rehash, 而 redis 为了性能考虑, 采用的是 渐进式 rehash.
常用命令
> hset books java "think in java" # 命令行的字符串如果包含空格,要用引号括起来
(integer) 1
> hset books golang "concurrency in go"
(integer) 1
> hset books python "python cookbook"
(integer) 1
> hgetall books # entries(),key 和 value 间隔出现
1) "java"
2) "think in java"
3) "golang"
4) "concurrency in go"
5) "python"
6) "python cookbook"
> hlen books
(integer) 3
> hget books java
"think in java"
> hset books golang "learning go programming" # 因为是更新操作,所以返回 0
(integer) 0
> hget books golang
"learning go programming"
> hmset books java "effective java" python "learning python" golang "modern golang programming" # 批量 set
OK
字典
Redis 的 Hash 是通过 dict 结构来实现的, 该结构的底层是由哈希表来实现.类似于 HashMap, 数组+链表, 超过负载因子所对应的阈值时,进行 rehash, 扩容. 在具体实现中,使用了渐进式hash的方式来避免 HashMap 这种阻塞式的 rehash, 将 rehash 的工作分摊到对字典的增删改查中.
struct
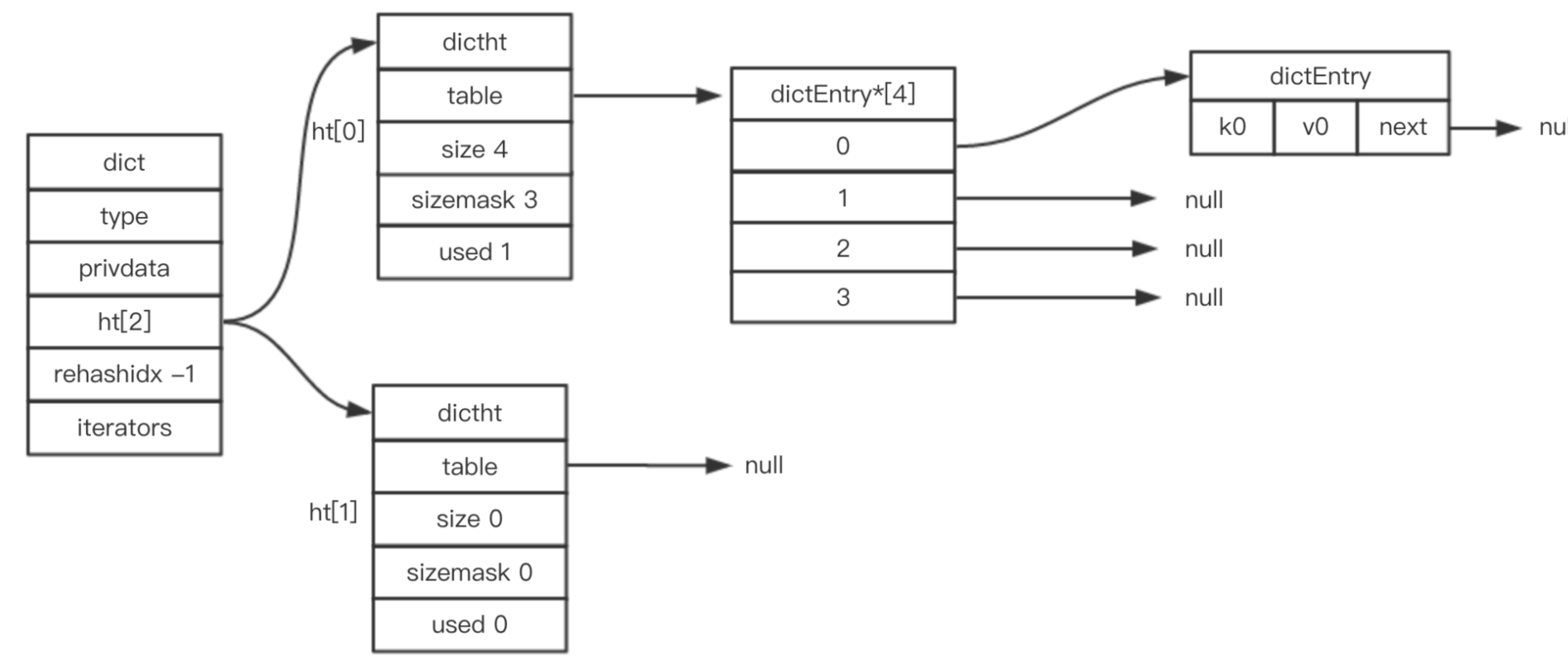
typedef struct dictEntry {
void *key; //键
union {
void *val; //值
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //指向下一节点,形成链表
} dictEntry;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; // 哈希表数组,数组的每一项都是 distEntry 的头结点
unsigned long size; // 哈希表的大小,也是触发扩容的阈值
unsigned long sizemask; // 哈希表大小掩码,用于计算索引值,总是等于 size-1
unsigned long used; // 哈希表中实际保存的节点数量
} dictht;
typedef struct dict {
dictType *type; //属性是一个指向 dictType 结构的指针,每个 dictType 结构保存了一簇用于操作特定类型键值对的函数,Redis 会为用途不同的字典设置不同的类型特定函数
void *privdata; // 保存了需要传给那些类型特定函数的可选参数
dictht ht[2]; // 在字典内部,维护了两张哈希表. 一般情况下,字典只使用 ht[0] 哈希表,ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用
long rehashidx; // 记录 rehash 的状态, 没有进行 rehash 则为 -1
unsigned long iterators; /* number of iterators currently running */
} dict;
一张图来表示
何时扩容?
找到dictAddRow 函数观察源码可以发现,会在 _dictExpandIfNeeded 函数中进行扩容的判断.
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
// 正在渐进式扩容, 就返回 OK
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
// 如果哈希表 ht[0] size 为 0 ,初始化, 说明 redis 是懒加载的,延长初始化策略
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
/*
* 如果哈希表ht[0]中保存的key个数与哈希表大小的比例已经达到1:1,即保存的节点数已经大于哈希表大小
* 且redis服务当前允许执行rehash,或者保存的节点数与哈希表大小的比例超过了安全阈值(默认值为5)
* 则将哈希表大小扩容为原来的两倍
*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这个时候就会强制扩容。
何时缩容?
当哈希表的负载因子小于 0.1 时,自动缩容.这个操作会在 redis 的定时任务中来完成.函数为 databasesCron,该函数的作用是在后台慢慢的处理过期,rehashing, 缩容.
执行条件: 没有子进程执行aof重写或者生成RDB文件
/* 遍历所有的redis数据库,尝试缩容 */
for (j = 0; j < dbs_per_call; j++) {
tryResizeHashTables(resize_db % server.dbnum);
resize_db++;
}
/* If the percentage of used slots in the HT reaches HASHTABLE_MIN_FILL
* we resize the hash table to save memory */
void tryResizeHashTables(int dbid) {
if (htNeedsResize(server.db[dbid].dict))
dictResize(server.db[dbid].dict);
if (htNeedsResize(server.db[dbid].expires))
dictResize(server.db[dbid].expires);
}
/* Hash table parameters */
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
int dictResize(dict *d)
{
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
从 htNeedsResize函数中可以看到,当哈希表保存的key数量与哈希表的大小的比例小于10%时需要缩容.最小容量为DICT_HT_INITIAL_SIZE = 4. dictResize 函数中,当正在执行 aof 重写或生成 rdb 时, dict_can_resize 会变为 0, 也就说明上面的 执行条件.
渐进式 rehash
从上述源码中可以看出,所有的扩容或者创建都经过 dictExpand 函数.
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
// 计算新的哈希表大小,获得大于等于size的第一个2次方
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// 第一次初始化也会通过这里来完成创建
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
// ht[1] 开始派上用场,扩容时是在 ht[1] 上操作, rehash 完毕后,在交换到 ht[0]
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
从 dictExpand 这个函数可以发现做了这么几件事:
- 校验是否可以执行
rehash - 创建一个新的哈希表
n, 分配更大的内存 - 将哈希表
n复制给ht[1], 将rehashidx标志置为 0 ,意味着开启了渐进式rehash. 该值也标志渐进式rehash当前已经进行到了哪个hash槽.
该函数没有将key重新 rehash 到新的 slot 上,而是交由增删改查的操作, 以及后台定时任务来处理.
增删改查辅助rehash
看源码其实可以发现在所有增删改查的源码中,开头都会有一个判断,是否处于渐进式rehash中.
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
...
}
// 进入 rehash 后是 >=0的值
#define dictIsRehashing(d) ((d)->rehashidx != -1)
/*
* 此函数仅执行一步hash表的重散列,并且仅当没有安全迭代器绑定到哈希表时。
* 当我们在重新散列中有迭代器时,我们不能混淆打乱两个散列表的数据,否则某些元素可能被遗漏或重复遍历。
*
* 该函数被在字典中查找或更新等普通操作调用,以致字典中的数据能自动的从哈系表1迁移到哈系表2
*/
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
后台任务rehash
虽然redis实现了在读写操作时,辅助服务器进行渐进式rehash操作,但是如果服务器比较空闲,redis数据库将很长时间内都一直使用两个哈希表.所以在redis周期函数中,如果发现有字典正在进行渐进式rehash操作,则会花费1毫秒的时间,帮助一起进行渐进式rehash操作.
还是上面缩容时使用的任务函数databasesCron.源码如下:
/* Rehash */
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
/* If the function did some work, stop here, we'll do
* more at the next cron loop. */
break;
} else {
/* If this db didn't need rehash, we'll try the next one. */
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
渐进式rehash弊端
渐进式rehash避免了redis阻塞,可以说非常完美,但是由于在rehash时,需要分配一个新的hash表,在rehash期间,同时有两个hash表在使用,会使得redis内存使用量瞬间突增,在Redis 满容状态下由于Rehash会导致大量Key驱逐.
Zset 有序集合
首先 zset 是一个 set 结构,拥有 set 的所有特性,其次他可以给每一个 value 赋予一个 score 作为权重.内部实现用的跳表(skiplist)
常用命令
ZADD,ZRANGE,ZREVRANGE,ZSCORE,ZCARD,ZRANK…
> zadd books 9.0 "think in java"
(integer) 1
> zadd books 8.9 "java concurrency"
(integer) 1
> zadd books 8.6 "java cookbook"
(integer) 1
> zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> zcard books # 相当于 count()
(integer) 3
> zscore books "java concurrency" # 获取指定 value 的 score
"8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题
> zrank books "java concurrency" # 排名
(integer) 1
> zrangebyscore books 0 8.91 # 根据分值区间遍历 zset
1) "java cookbook"
2) "java concurrency"
> zrangebyscore books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代表 infinite,无穷大的意思。
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> zrem books "java concurrency" # 删除 value
(integer) 1
> zrange books 0 -1
1) "java cookbook"
2) "think in java"
数据结构
众所周知, Zset 是一个有序的set集合, redis 通过 hash table 来存储 value 和 score 的映射关系,可以达到 O(1), 通过 score 排序或者说按照 score 范围来获取这个区间的 value, 则是通过 跳表 来实现的. Zset 可以达到 O(log(N)) 的插入和读写.
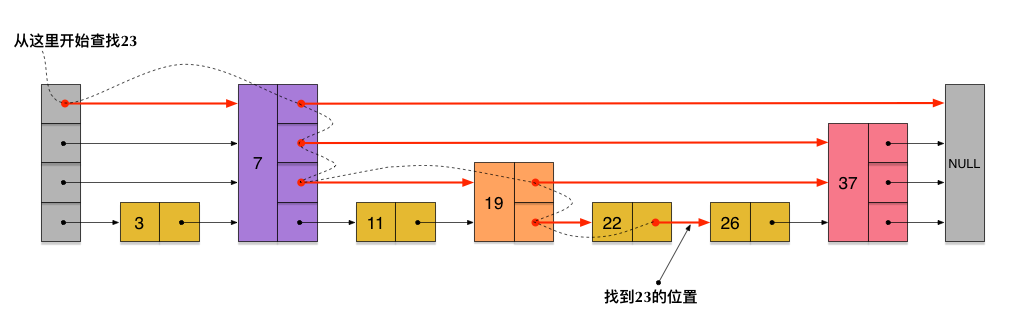
什么是跳跃列表?

如图,跳跃列表是指具有纵向高度的有序链表.跳表会随机的某提升些链表的高度,并将每一层的节点进行连接,相当于构建多级索引,这样在查找的时候,从最高层开始查,可以过滤掉一大部分的范围,有点类似于二分查找.跳表也是典型的空间换时间的方式.
每一个 kv 块对应的结构如下面的代码中的zslnode结构,kv header 也是这个结构,只不过 value 字段是 null 值——无效的,score 是 Double.MIN_VALUE,用来垫底的。
struct
struct zslnode {
string value;
double score;
zslnode*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
struct zsl {
zslnode* header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map<string, zslnode*> ht; // hash 结构的所有键值对
}
redis中跳表的优化
- 允许 score 是重复的
- 比较不仅是通过 key(即 score), 也还会比较 data
- 最底层(
Level 1)是有反向指针的,所以是一个双向链表,这样适用于从大到小的排序需求(ZREVRANGE)
一次查找的过程
redis中level是如何生成的?
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
ZSKIPLIST_MAXLEVEL 最大值是 64, 也就是最多 64 层.ZSKIPLIST_P 为 1/4, 也就是说有 25% 的概率有机会获得level,要获得更高的level,概率更小. 这也就导致了, redis中的跳表层级不会特别高,较扁平,较低层节点较多.有个小优化的地方: 跳表会记录下当前的最高层数 MaxLevel 这样就不需要从最顶层开始遍历了.
为什么使用跳表而不是红黑树或者哈希表?
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
- 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。

