之前对redis 的复制只有一点点了解,这次想要搞明白的是:如何实现的复制? 复制会遇到哪些问题(时延/一致性保证/网络故障时的处理)? 如何解决?高可用实现方案?
文章有部分是直接翻译的 https://redis.io/topics/replication
复制是什么?
分布式系统有一个重要的点时保证数据不丢失,数据不丢失就意味着不能单点,不能单点就意味着最好能把数据多存几份形成数据的冗余.这就是复制的来由.复制类型主要是两种: 同步, 异步. 前者需要等待所有的节点返回写入确认,后者只需要返回个确认收到就行.
Redis 主从复制
主从复制作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
Redis 复制设计要点
默认使用异步复制 – replica -> master 异步返回处理了多少数据的结果(偏移量)
master可以多replicasreplicas可以从其他replica同步(从从复制).类似于级联更新的架构.
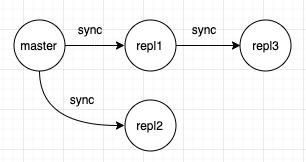
master主节点在同步时不会阻塞.- 在
replica侧复制也是非阻塞的.在进行初始化同步(全量)时,可以使用replica上的旧数据供客户端查询.也可以在redis.conf进行配置,在初始化同步完成前客户端的请求都报错.初始化同步完成后,需要删除老数据,加载新数据.在这段时间中会阻塞外部连接请求,数据量大的话可能要很久.从4.0版本后,删除老数据可以通过多线程来优化效率,但是加载新数据还是会 阻塞. - 复制可以用来弹性扩容,提供多可读副本,提升数据安全性,保证高可用
- 副本可以避免
master保存全量数据到磁盘的资源消耗:可以由replica完成持久化,或者开启aof写入.不过需要慎重: 这样会导致master节点再重启时会是空的,其他replica复制时也就成空的了.
主从复制过程
每一个 master 节点都会有一个特别大的随机数(40字节十六进制随机字符)作为 replication ID 来标识自己.每个 master 节点也有一个 持续递增的 offset 来记录发送给 replicas 的每一个 byte,利用该 offset 来保证副本更新的状态.
当一个 replica 连接到 master 时,会使用 PSYNC 命令发送之前复制的 master 的 replicationID,以及自己的更新进度(offset).master 可以根据这个值给副本按需返回为更新的数据.如果在master 的 backlog buffer 中没有对应的数据可以给到,副本发送的 replicationID 与 master 的 ID 不一致,就会触发全量复制(Full Synchronization).
backlog buffer 是啥?
复制积压缓冲区,在 master 有 replica 进行复制时,存储 master 最近一段时间的写命令,以便在 replica 断开重连后,可以利用缓冲区更新断开这段时间中,从节点丢掉的更新.
backlog buffer 是有固定的长度,先进先出的队列,默认大小 1MB. 其实就是一个环.buffer 会存储每一个 offset 已经对应的写命令,这样 replica 在断连恢复后,发送 PSYNC 命令提供其最后一次更新的 offset, master 就可以根据 replica 提供的 offset 去 buffer 中找对应的数据发送给 replica 保持最新.
如果断开时间过长,buffer 存储的数据已经换了一批又一批, replica 在重连后发送给 master 的 offset 在 buffer 已经找不到了.此时会触发 全量复制.
全量复制
master调用 bgsave 在后台生成 rdb 文件.同时记录客户端新的写命令到 backlog buffer 中. rdb 文件生成后,发送给 replica 保存到其硬盘中,然后再加载到内存中并通知master 加载完成.然后 master 会发送 buffer pool 中的命令给 replica 完成最后的同步.
SYNC/PSYNC
两者都是同步的命令.SYNC 只支持全量同步, PSYNC 支持上述的部分同步.2.8 版本之前只有 SYNC,为了避免每次都只能全量同步造成资源的浪费,就新增了 PSYNC 命令实现部分同步的语义.
Replication ID
Replication ID 标记了数据的历史信息,从0开始成为master 的节点,或者晋升成为 master 的 replica 节点,都会生成一个 Replication ID.replicas 的 replId 是和其复制的 master 一致的,master 通过该 ID 和 offset 来判断主从之间数据是否一致.
为什么有两个replId?
/* src/server.h */
struct redisServer {
...
/* Replication (master) */
char replid[CONFIG_RUN_ID_SIZE+1]; /* My current replication ID. */
char replid2[CONFIG_RUN_ID_SIZE+1]; /* replid inherited from master*/
...
long long master_repl_offset; /* My current replication offset */
long long second_replid_offset; /* Accept offsets up to this for replid2. */
...
}
一般情况下,故障转移(failover)后,晋升的 replica 需要记录自己之前复制的 master 对应的 replId.其他 replicas 会向新 master 进行部分同步,但发送过来的 replId 还是之前 master 的.所以 replica 在晋升时,会生成新的replId,并将原来的 replId 记录到 replId2,同时记录下当时所更新到的 offset 到 second_replid_offset.当其他的 replica 向新 master 进行连接时,新 master 会比较当前的和之前 master 的 replId,offset,这样就可以防止在故障转移后导致不必要的 全量复制.
为什么晋升后需要生成新 replId?
old master 可能还存活,但由于网络分区原因无法和其他 replicas 通信,如果保留原来的 id 不再生成,就会导致有相同数据相同id的master 存在.
无盘复制
全量复制时,master 会创建 rdb 文件存到磁盘,然后再读取 rdb 文件发送给 replicas.磁盘性能差的情况下,效率会很低,所以支持了 无盘复制 – 子进程直接发送 rdb 给 replicas,不经过硬盘存储.
如何处理可以过期的键?
- 副本不会主动去过期键,而是由
master过期键后向副本发送DEL命令. - 由于是通过
master驱动,副本收到DEL命令可能有延迟,这就会导致从副本中还可能查到已过期的键.针对这种情况,副本会利用自身的物理时钟作为依据报告该键不存在(仅在不违反数据一致性的 只读操作),因为DEL命令总是会发过来的. LUA脚本执行期间,是不会去执行key过期的.脚本执行期间相当于master时间冻结了,不作过期时间的记录,所以在这期间过期键只有存在或不存在的概念.这样可以防止键在执行期间过期.同时,master也需要发送同样的脚本给副本,保持一致.
如果replica 晋升 master 了,它就会自己去处理键的过期了.
心跳机制
在正常的进行 部分同步 期间,主从之间会维持心跳,来协助超时判断,数据安全等问题.
master -> slave
主节点发送 PING ,从节点回复 PONG.目的是让从节点进行超时判断.发送频率有 repl-ping-slave-period 参数控制.单位秒,默认 10s.
replica -> master
从节点向主节点发送 REPLCONF ACK {offset} ,频率每秒1次.作用:
- 试试检测主从网络状态,该命令被主节点用于复制超时的判断.
- 检测命令丢失,主节点会比较从节点发送的
offset与自身的是否一致,不一致则从buffer中查找对应数据进行补发,如果buffer中没有对应数据,则会进行全量复制. - 辅助保证从节点的数量和延迟,
master通过min-salves-to-write和min-slaves-max-lag参数,来保证主节点在不安全情况下不会执行写命令.是指从节点数量太少,或延迟过高。例如min-slaves-to-write和min-slaves-max-lag分别是3和10,含义是如果从节点数量小于3个,或所有从节点的延迟值都大于10s,则主节点拒绝执行写命令。
复制惨痛案例
数据过期问题
数据删除没有及时同步到从节点,其实在 3.2 版本后避免了这个问题.从节点会对键进行判断,已过期不展示.
数据延迟不一致
这种情况不可避免.可能的优化措施包括:优化主从节点之间的网络环境(如在同机房部署);监控主从节点延迟通过offset判断,如果从节点延迟过大,通知应用不再通过该从节点读取数据;使用集群同时扩展写负载和读负载等。
复制超时导致复制中断
为什么要判断超时?
master在判断超时后,会释放从节点的连接,释放资源.- 断开后即时重连
判断机制?
核心参数: repl-timeout ,默认 60s.
(1)主节点:每秒1次调用复制定时函数replicationCron(),在其中判断当前时间距离上次收到各个从节点 REPLCONF ACK 的时间,是否超过了 repl-timeout 值,如果超过了则释放相应从节点的连接。
(2)从节点:从节点对超时的判断同样是在复制定时函数中判断,基本逻辑是:
- 如果当前处于连接建立阶段,且距离上次收到主节点的信息的时间已超过
repl-timeout,则释放与主节点的连接; - 如果当前处于数据同步阶段,且收到主节点的
RDB文件的时间超时,则停止数据同步,释放连接; - 如果当前处于命令传播阶段,且距离上次收到主节点的
PING命令或数据的时间已超过repl-timeout值,则释放与主节点的连接。
问题
- 全量复制时,如果
RDB文件过大,耗时很长就会触发超时,此时从节点会重连,再生成RDB,再超时,在生成RDB…解决方案就是单机数据量尽量不要太大,增大repl-timeout. - 慢查询导致服务器阻塞:
keys *,hgetall
backlog 过小导致无限全量复制
backlog buffer 是固定大小的,写入命令超出长度就会覆盖.如果再全量复制的时候用时超长,存入buffer 的命令超过了其大小限制,那么就会导致连接中断,再重连,全量复制,连接中断,全量复制….死循环.解决方案就是需要正确设置 backlog buffer 的大小. 通过 client-output-buffer-limit slave {hard limit} {soft limit} {soft seconds} 配置,默认值为 client-output-buffer-limit slave 256MB 64MB 60,其含义是:如果 buffer 大于256MB,或者连续 60s 大于 64MB ,则主节点会断开与该从节点的连接。该参数是可以通过 config set 命令动态配置的(即不重启Redis也可以生效).
参考
「Redis 设计与实现」

