
diff options
| author | nicholas-leonard <nick@nikopia.org> | 2016-07-20 18:55:44 +0300 |
|---|---|---|
| committer | nicholas-leonard <nick@nikopia.org> | 2016-07-20 18:55:44 +0300 |
| commit | 259333edd7df4be28257aa7e08b92e79e9aefbf1 (patch) | |
| tree | ee9d9dc6dd22869ca5fbfd41f5a62f2983c20889 | |
| parent | 21bb018b80ad29f73910c3557020a320c6e0d659 (diff) | |
nce++
| -rw-r--r-- | blog/_posts/2016-05-11-nce.md | 127 |
1 files changed, 70 insertions, 57 deletions
diff --git a/blog/_posts/2016-05-11-nce.md b/blog/_posts/2016-05-11-nce.md index 11ee839..195579c 100644 --- a/blog/_posts/2016-05-11-nce.md +++ b/blog/_posts/2016-05-11-nce.md @@ -7,12 +7,28 @@ excerpt: TODO picture: https://raw.githubusercontent.com/torch/torch.github.io/master/blog/_posts/images/output_52iFki.gif --- -<!---# Noise Contrastive Estimation --> - -In the past couple of months we have seen increased interest in generative character-level -recurrent neural network (RNN) models like [char-rnn](https://github.com/karpathy/char-rnn) +<!---# Noise contrastive estimation for the Google billion words dataset --> + + * Word versus character level language models + * Recurrent neural network language models + * Loading the Google billion words dataset + * Building a multi-layer LSTM + * Training and evaluation scripts + * Results + +In this blog post, we use Torch to use noise contrastive estimation (NCE) [[2]](#nce.ref) +to train a multi-GPU recurrent neural network language model (RNNLM) +on the Google billion words (GBW) dataset [[7]](#nce.ref). +This blog post is the result of many months of work. +The enormity of the dataset caused us to contribute some novel open-source modules, criteria and even a multi-GPU tensor. +We also provide scripts so that you can train and evaluate your own language models. + +## Word versus character level language models + +In recent months you may have noticed increased interest in generative character-level +RNNLMs like [char-rnn](https://github.com/karpathy/char-rnn) and the more recent [torch-rnn](https://github.com/jcjohnson/torch-rnn). -These models are very interesting as they can be used to generate sequences of text like: +These models are very interesting as they can be used to generate sequences of characters like the following: ```lua <post> @@ -27,16 +43,14 @@ the developers built or trying to run the patch to Jagex. ``` The above was generated one character at a time using a sample of [reddit](https://www.reddit.com/) comments. -As you can see for yourself, the general structure of the generated text looks good at first view. +As you can see for yourself, the general structure of the generated text looks good, at first view. The tags are opened and closed appropriately. The first sentence looks good: `I liked this game so much!!` and it is related to the subreddit of the post: `Diablo`. But reading the rest of it, we can start to see the limitations of char-level language models. The spelling of individual words looks great, but -the meaning of the next sentence is difficult to understand. - -## Word-Level vs Char-Level Language Models +the meaning of the next sentence is difficult to understand (it is also very long). In this blog post we will show how Torch can be used to train a large-scale word-level language model to generate -independent sentences. Word-level models have an important advantage of char-level models. +independent sentences. Word-level models have an important advantage over char-level models. Take the following sequence as an example (a quote from Robert A. Heinlein): ``` @@ -53,30 +67,22 @@ have a really small vocabulary. For example, the Google Billion Words dataset wi compared to 800,000 words (after pruning low-frequency tokens). In practice this means that char-level models will require less memory and have faster inference than their word-level counterparts. -## Output Layer Bottleneck +## Recurrent neural network language models -With its small vocabulary of 10000 words, the Penn Tree Bank dataset is relatively easy to use to build word-level language models. -The output layer is still tractable to compute for both training and inference, especially for GPUs. -For these smaller vocabularies, the output layer is basically a `Linear` followed by a `SoftMax`: +Our task is to build a language model which will maximize the likelihood of the +next word given the history of previous words in the sentence. +The following figure illustrates the a Simple Recurrent Neural Network (Simple RNN) language model: -```lua -outputlayer = nn.Sequential() - :add(nn.Linear(hiddensize, vocabsize)) - :add(nn.SoftMax()) -``` + -However, when training with large vocabularies, like the 793471 words that makes up -the Google Billion Words (GBW) dataset [[1]](#nce.ref), -the output layer quickly becomes a bottle neck. -If you are training your model with a `batchsize = 32` (number of sequences per batch) and a `seqlen = 100` -(size of sequence to backpropagate through time), -the output of that layer will have shape `seqlen x batchsize x vocabsize`, or `32 x 100 x 793471`. -For a `FloatTensor` or `CudaTensor`, that single tensor will take up 10.156GB of memory. -The number can be double for gradients, and doubled again as both Linear and SoftMax store a copy for the output. -If somehow you can find a way to put >40GB on a GPU (or distribute it over many), you then run in the problem of -forward/backward propagating through that `outputlayer` in a reasonable time-frame. +So for this particular example, the model should maximize "is" given "what", and then "the" given "is" and so on. +The RNN has an internal hidden state `h[t]` which summarizes the sequence fed in so far, as it relates to maximizing the following target words. +Simple RNNs are not the only kind of model that can be used model language. +There are also the more advanced Long Short Term Memory (LSTM) models [[3],[4],[5]](#nce.ref), which +have special gated cells that facilitate the backpropagation of gradients through longer sequences. +LSTMs can learn dependencies seperated by much longer time-steps . -## GBW Data Loader +## Loading the Google billion words dataset For our word-level language model we use the GBW dataset. The dataset is different from Penn Tree Bank in that sentences are @@ -233,24 +239,9 @@ means that the data is iterated in sequence. Each sentence in the GBW dataset is encapsulated by `<S>` and `</S>` tokens to indicate the start and end of the sequence, respectively. Each token is mapped to an integer. So for example, you can see that `<S>` is mapped to integer `793470` in the above example. -Now that we feel confident in our dataset, lets look at the model. - -## RNNLM - -Our task is to build a language model which will maximize the likelihood of the -next word given the history of previous words in the sentence. -The following figure illustrates the a Simple Recurrent Neural Network (Simple RNN) language model: - -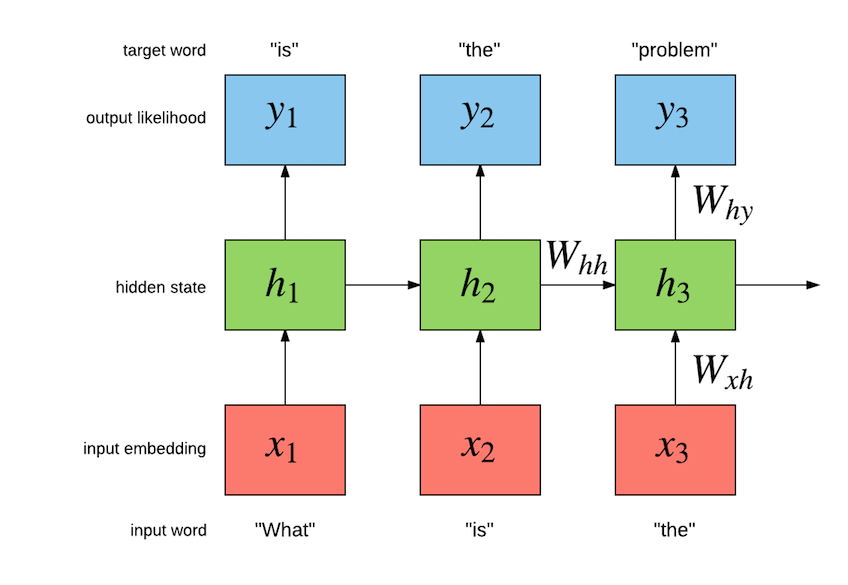 - -So for this particular example, the model should maximize "is" given "what", and then "the" given "is" and so on. -The RNN as an internal hidden state `h[t]` which summarizes the sequence fed in so far, as it relates to maximizing the following target words. -Simple RNNs are not the only kind of model that can be used model language. -There are also the more advanced Long Short Term Memory (LSTM) models [[3],[4],[5]](#nce.ref), which -have special gated cells that facilitate the backpropagation of gradients through longer sequences. -LSTMs can learn dependencies seperated by much longer time-steps . +Now that we feel confident in our dataset, lets look at the model. -## Multi-layer LSTM +## Building a multi-layer LSTM The input layer of the the `lm` model is a lookup table : @@ -287,7 +278,29 @@ each time-step: lm:add(nn.SplitTable(1)) ``` -### Noise Contrastive Estimation +### Output layer bottleneck + +With its small vocabulary of 10000 words, the Penn Tree Bank dataset is relatively easy to use to build word-level language models. +The output layer is still computationally tractable for both training and inference, especially for GPUs. +For these smaller vocabularies, the output layer is basically a `Linear` followed by a `SoftMax`: + +```lua +outputlayer = nn.Sequential() + :add(nn.Linear(hiddensize, vocabsize)) + :add(nn.SoftMax()) +``` + +However, when training with large vocabularies, like the 793471 words that makes up the GBW dataset , +the output layer quickly becomes a bottle neck. +If you are training your model with a `batchsize = 32` (number of sequences per batch) and a `seqlen = 100` +(size of sequence to backpropagate through time), +the output of that layer will have shape `seqlen x batchsize x vocabsize`, or `32 x 100 x 793471`. +For a `FloatTensor` or `CudaTensor`, that single tensor will take up 10.156GB of memory. +The number can be double for gradients, and doubled again as both Linear and SoftMax store a copy for the output. +If somehow you can find a way to put >40GB on a GPU (or distribute it over many), you then run in the problem of +forward/backward propagating through that `outputlayer` in a reasonable time-frame. + +### Noise contrastive estimation The output layer of the LM uses Noise Contrastive Estimation (NCE) to speed up training and reduce memory consumption: @@ -340,11 +353,11 @@ Reference [[2]](#nce.ref) implement a faster version where the noise samples are This make the code a bit faster as the more efficient [torch.addmm](https://github.com/torch/torch7/blob/master/doc/maths.md#torch.addmm) can be used. This faster NCE version described in [[2]](#nce.ref) is the default implementation of the `NCEModule`. Sampling per batch-row can be turned on with `NCEModule.rownoise=true`. -## Scripts +## Training and evaluation scripts The experiments presented here use three scripts: two for training and one for evaluation. -### Single-GPU Training Script +### Single-GPU training script We provide training scripts for a single gpu via the [noise-contrastive-estimate.lua](https://github.com/Element-Research/rnn/blob/master/examples/noise-contrastive-estimate.lua) script. Running the following on a 12GB NVIDIA Titan X should resulted in a test set perplexity of 65.6 after 321 epochs: @@ -377,8 +390,9 @@ nn.Serial @ nn.Sequential { To use about one third less memory, you can set momentum of 0. -### Evaluation Script +### Evaluation script +The evaluation script can be used to measure perplexity on the test set or sample independent sentences. To evaluate a saved model, you can use the [evaluate-rnnlm.lua](https://github.com/Element-Research/rnn/blob/master/scripts/evaluate-rnnlm.lua) script: ```bash @@ -407,11 +421,10 @@ The `--temperature` flag can be reduced to make the sampling more deterministic. <S> It was last modified at 23.31 GMT on Saturday 22 December 2009 . </S> <S> He told the newspaper the prosecution had been treating the small boy as " a young man who was playing for a while . </S> <S> " We are astounded that our employees are not made aware of the risks and risks they are pursuing during this period of time , " he said . </S> -<S> " I had a right to come up with the idea . </S> -<S> But the truth +<S> " I had a right to come up with the idea . </S> ``` -### Multi-GPU Training Script +### Multi-GPU training script As can be observed in the previous section, training a 2-layer LSTM with only 250 hidden units will not yield the best generated samples. The model needs much more capacity than what can fit on a 12GB GPU. @@ -543,7 +556,7 @@ nn.Serial @ nn.Sequential { ## Results On the 4-layer LSTM with 2048 hidden units, [[1]](#nce.ref) obtain 43.2 perplexity on the GBW test set. -After early-stopping on a sub-set of the validation set (at 100 epochs of training), our model was able to reach *40.61* perplexity. +After early-stopping on a sub-set of the validation set (at 100 epochs of training where 1 epoch is 128 sequences x 400k words/sequence), our model was able to reach *40.61* perplexity. This model was run on 4x12GB NVIDIA Titan X GPUs. Training requires approximately 40GB of memory, distributed across the 4 GPU devices. @@ -551,7 +564,7 @@ As in the original paper, we do not make use of momentum as it provides little b Training runs at about 3800 words/second. -### Generated Samples +### Generating Sentences Here are 8 sentences sampled independently from the 4-layer LSTM with a `temperature` or 0.7: @@ -566,7 +579,6 @@ Here are 8 sentences sampled independently from the 4-layer LSTM with a `tempera <S> Later he was driven to a nearby house where he was later found to be severely ill . </S> ``` -Not bad, right? ### Learning Curves @@ -581,3 +593,4 @@ Not bad, right? 4. *S Hochreiter, J Schmidhuber*, [Long Short Term Memory](http://web.eecs.utk.edu/~itamar/courses/ECE-692/Bobby_paper1.pdf) 5. *A Graves, A Mohamed, G Hinton*, [Speech Recognition with Deep Recurrent Neural Networks](http://arxiv.org/pdf/1303.5778.pdf) 6. *K Greff, RK Srivastava, J Koutník*, [LSTM: A Search Space Odyssey](http://arxiv.org/pdf/1503.04069) +7. *C Chelba, T Mikolov, M Schuster, Q Ge, T Brants, P Koehn, T Robinson*, [One billion word benchmark for measuring progress in statistical language modeling](http://arxiv.org/pdf/1312.3005) |