
diff options
| author | Soumith Chintala <soumith@fb.com> | 2016-07-26 00:52:34 +0300 |
|---|---|---|
| committer | Soumith Chintala <soumith@fb.com> | 2016-07-26 00:52:34 +0300 |
| commit | c6818d3e2be3af1dadf8eba69f52f4fc915eeb42 (patch) | |
| tree | a64b8597b3cc03708cbacbe5fd36f2207310af5c | |
| parent | e8b9e3485a7333f041d6203b5dbb65ca0e71337b (diff) | |
fixing links
| -rw-r--r-- | blog/_posts/2016-07-25-nce.md | 14 |
1 files changed, 7 insertions, 7 deletions
diff --git a/blog/_posts/2016-07-25-nce.md b/blog/_posts/2016-07-25-nce.md index 7aa92e1..2bd1641 100644 --- a/blog/_posts/2016-07-25-nce.md +++ b/blog/_posts/2016-07-25-nce.md @@ -83,7 +83,7 @@ Our task is to build a language model which maximizes the likelihood of the next word given the history of previous words in the sentence. The following figure illustrates the workings of a simple recurrent neural network (Simple RNN) language model: - +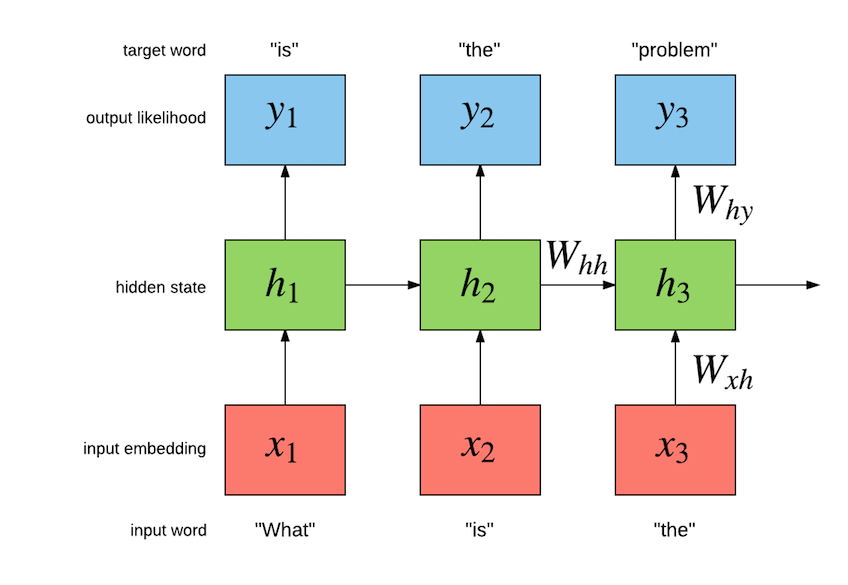 The exact implementation is as follows: @@ -111,7 +111,7 @@ but they are not the only kind of model that can be used model language. There are also the more advanced Long Short Term Memory (LSTM) models [[3],[4],[5]](#nce.ref), which have special gated cells that facilitate the backpropagation of gradients through longer sequences. - +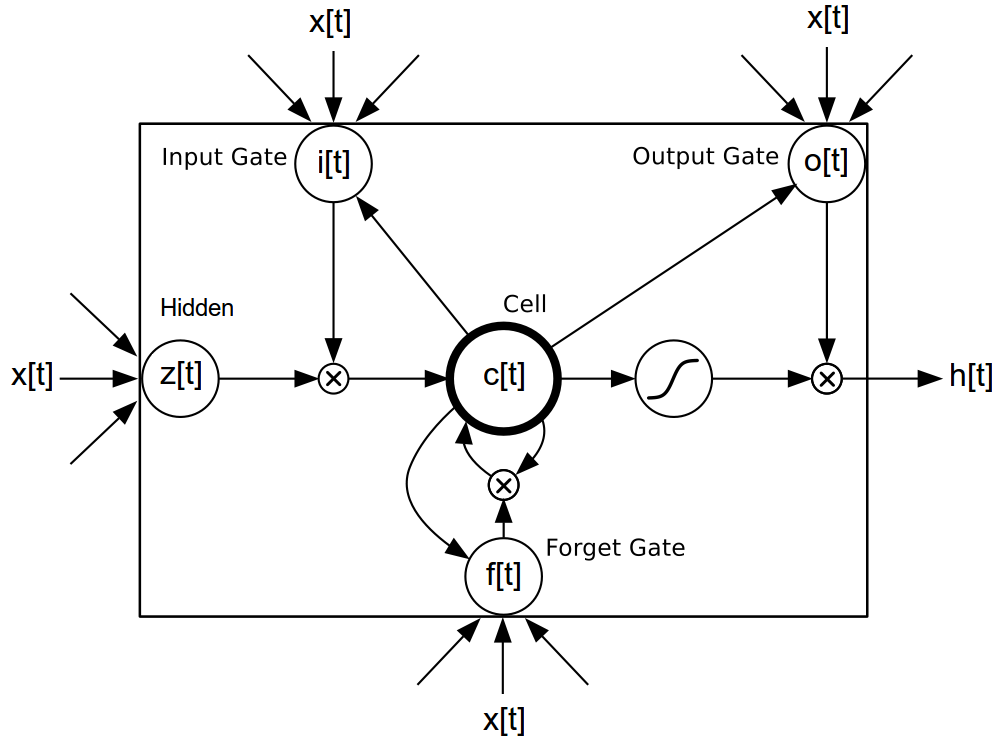 The exact implementation is as follows: @@ -366,7 +366,7 @@ For a `FloatTensor` or `CudaTensor`, that single tensor will take up 20GB of mem The number can be double for `gradInput` (i.e. gradients with respect to input), and double again as both `Linear` and `SoftMax` store a copy for the `output`. - +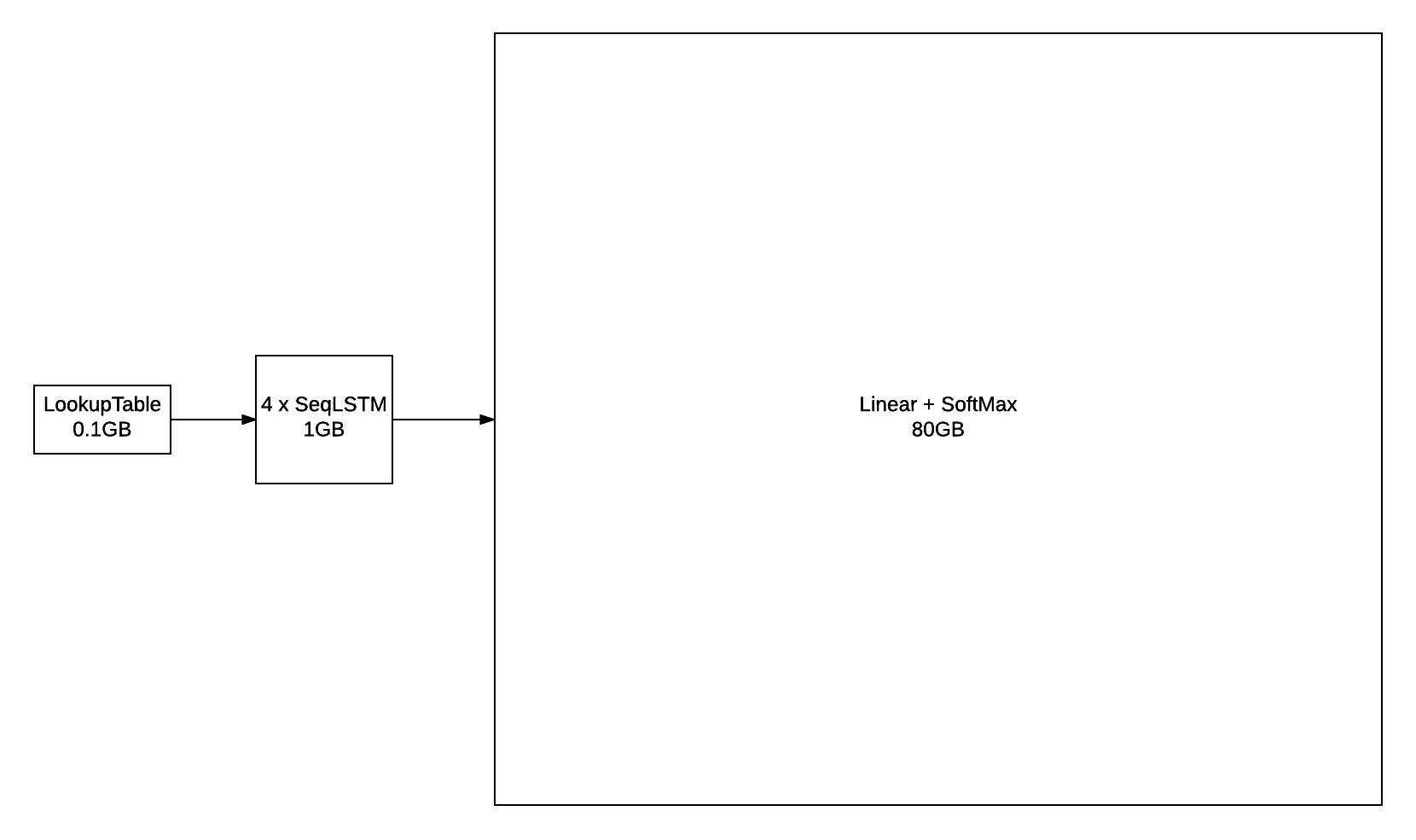 Excluding parameters and their gradients, the above figure outlines the approximate memory consumption of a 4-layer LSTM with 2048 units with a `seqlen=50`. Even if somehow you can find a way to put 80GB on a GPU (or distribute it over many), you still run into the problem of @@ -400,7 +400,7 @@ nn.Sequential():add(nn.Linear(inputsize, #trainset.ivocab)):add(nn.LogSoftMax()) For evaluating perplexity, the model still implements `Linear` + `SoftMax`. NCE is useful for reducing the memory consumption during training (compare to the figure above): - +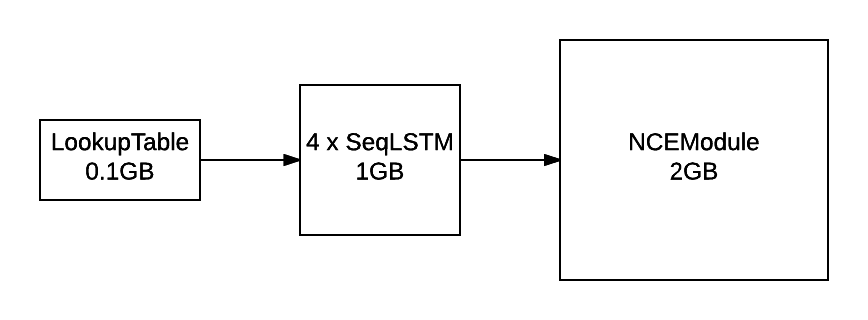 Along with the [NCECriterion](https://github.com/Element-Research/dpnn#nn.NCECriterion), the `NCEModule` implements the algorithm is described in [[1]](#nce.ref). @@ -541,7 +541,7 @@ As can be observed in the previous section, training a 2-layer LSTM with only 25 generated samples. The model needs much more capacity than what can fit on a 12GB GPU. For parameters and their gradients, a 4x2048 LSTM model requires the following: - +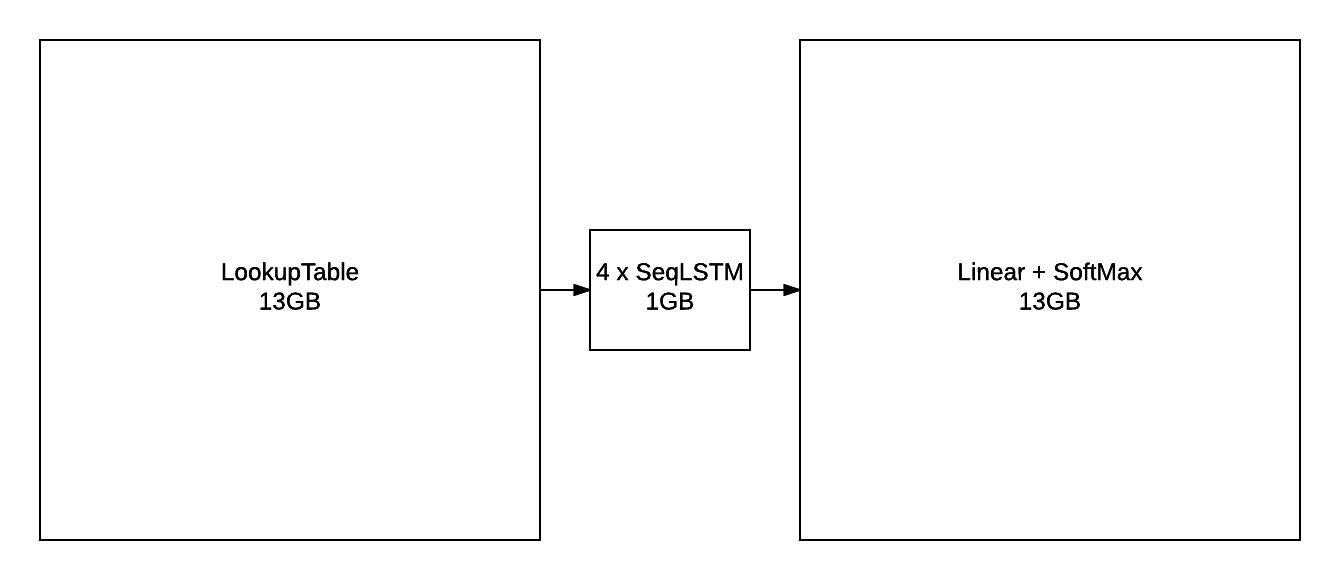 This doesn't include all the intermediate buffers required for the different modules (outlined in [NCE section](#nce.nce)). The solution was of course to distribution the model over more GPUs. @@ -687,14 +687,14 @@ The following figure outlines the learning curves for the above 4x2048 LSTM mode The figure plots the NCE training and validation error for the model, which is the error output but the `NCEModule`. Test set error isn't plotted as doing so for any epoch requires about 3 hours because test set inference uses `Linear` + `SoftMax` with `batchsize=1`. - +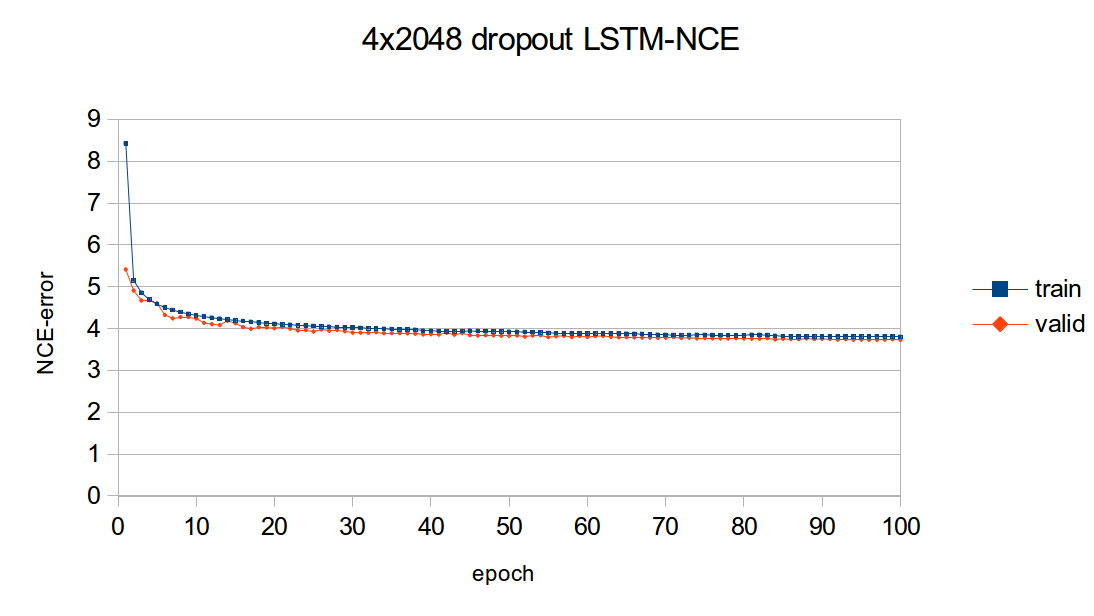 As you can see, most of the learning is done in the first epochs. Nevertheless, the training and validation error are consistently reduced training progresses. The following figure compares the valiation learning curves (again, NCE error) for a small 2x250 LSTM (no dropout) and big 4x2048 LSTM (with dropout). - +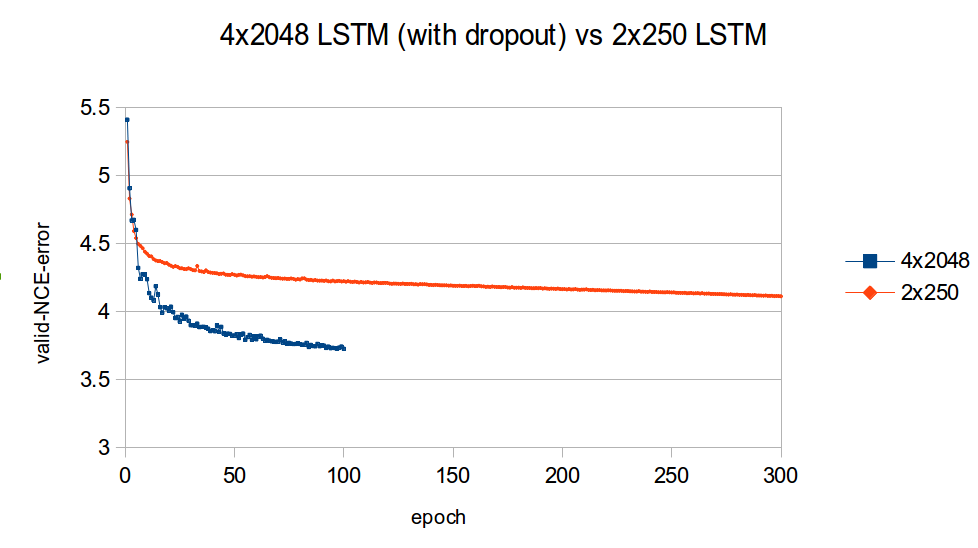 What I find impressive about this figure is how quickly the higher-capacity model bests the lower-capacity model. This clearly demonstrates the importance of capacity when optimizing large-scale language models. |